
简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统,简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
Hadoop的核心设计是:HDFS、YARN和MapReduce。HDFS为海量的数据提供了存储,YARN提供资源调度,而MapReduce则为海量的数据提供了计算.
环境
系统环境
为了避免防火墙等影响 默认已经关闭iptables和selinux
| 身份 | 系统 | 主机名 | IP |
|---|---|---|---|
| Hadoop master | ubuntu 16.04 | master | 10.0.0.3 |
| Hadoop slave1 | ubuntu 16.04 | slave1 | 10.0.0.4 |
| Hadoop slave2 | ubuntu 16.04 | slave2 | 10.0.0.5 |
| Hadoop slave3 | ubuntu 16.04 | slave3 | 10.0.0.6 |
软件环境
| 软件名称 | 版本号 | 下载地址 |
|---|---|---|
| Hadoop | 2.7.5 | 点击下载 |
| jdk | 1.8.0_161 | 点击下载 |
步骤
安装Hadoop
下载的是官方编译好的二进制包 所以就不用再重新编译了。
注意:下面的操作需要在所有主机上进行 或者配置好一台后rsync同步到其他主机
下载和解压
1 | # 软件包在windows上下载并上传到了Linux上 注意jdk下载需要先接受许可协议 |
配置集群环境
集群环境为启动和使用Hadoop集群所需要的配置
配置jdk环境变量
将以下内容写入到
/etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
修改
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到 export JAVA_HOME=${JAVA_HOME}
修改为 export JAVA_HOME=/usr/local/jdk1.8.0_161
配置hadoop环境变量
将以下内容写入到
/etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使环境变量立即生效
运行命令:
1 | source /etc/profile |
配置主机名解析
将以下内容写入到
/etc/hosts
10.0.0.3 master
10.0.0.4 slave1
10.0.0.5 slave2
10.0.0.6 slave3
Windows上也顺便更改下hosts文件 以便于后面的访问集群
hosts文件位置:C:\Windows\System32\drivers\etc\hosts
因为系统目录权限问题 可以将hosts文件拖到桌面修改后再拖回去覆盖了原文件即可
认识HDFS
HDFS的全称是 “Hadoop分布式文件系统” ,可以简单理解为由用户进程模拟的一块大硬盘,为大数据处理提供了基础的数据存储服务,下面先看看HDFS是怎么一回事,再探究它到底是个什么东东。
启动HDFS
Hadoop由三部分组成 HDFS则是其最基层的一部分。
配置文件语法
Hadoop的配置文件在
/usr/local/hadoop/etc/hadoop/中,配置文件使用xml语法
<property> <!-- 属性 -->
<name></name> <!-- 名称 -->
<value></value> <!-- 值 -->
</property>
配置项需要写在配置文件的<configuration></configuration>代码块中
配置文件简单介绍
Hadoop可能需要经常改动的配置文件有四个,下面简单说说这四个都是干嘛用的,具体用到的配置文件,后面会详细说明。
| 配置文件 | 说明 |
|---|---|
| core-site.xml | Hadoop Core的配置项 |
| hdfs-site.xml | HDFS的配置项 比如配置HDFS数据存储位置等 |
| yarn-site.xml | yarn资源调度器的配置 比如yarn监听的地址等 |
| mapred-site.xml | MapReduce计算引擎的相关配置 |
修改配置文件
HDFS的配置文件为
hdfs-site.xml打开发现<configuration></configuration>中是空的。其实Hadoop已经为HDFS的各种参数配置了默认值,用户重写进配置文件的值会覆盖掉Hadoop默认的。启动HDFS集群需要让各slave节点知道要连接谁,而这个配置是在core-site.xml中。
将所有节点的
core-site.xml修改为如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
配置hdfs的slave都连接master的9000端口
启动HDFS集群
HDFS集群分为 NameNode 和 DataNode ,其中NameNode为master节点 DataNode为slave节点
NameNode的作用就像一本书的目录 记录每一个文件存放在哪个slave节点上。而DataNode则是存放数据用的了。
启动前需要先对namenode进行目录格式化
在master节点上执行NameNode格式化命令和启动的命令1
2hadoop namenode -format
hadoop-daemon.sh start namenode
在所有slave节点上执行启动DataNode的命令1
hadoop-daemon.sh start datanode
使用jps命令可以看到当前启动的java进程,可以看到master节点跑着的是NameNode进程,而slave节点跑着的是DataNode进程
验证是否启动成功
HDFS启动成功后 master会监听9000端口,并且还会监听50070端口,这个端口是HDFS的web管理界面。
可以使用命令的方式查看集群各节点的运行状况1
hdfs dfsadmin -report
也可以在web界面上直观的看到HDFS集群的状况
浏览器访问:http://master:50070 然后点击 Datanodes 可以看到三个slave正常在线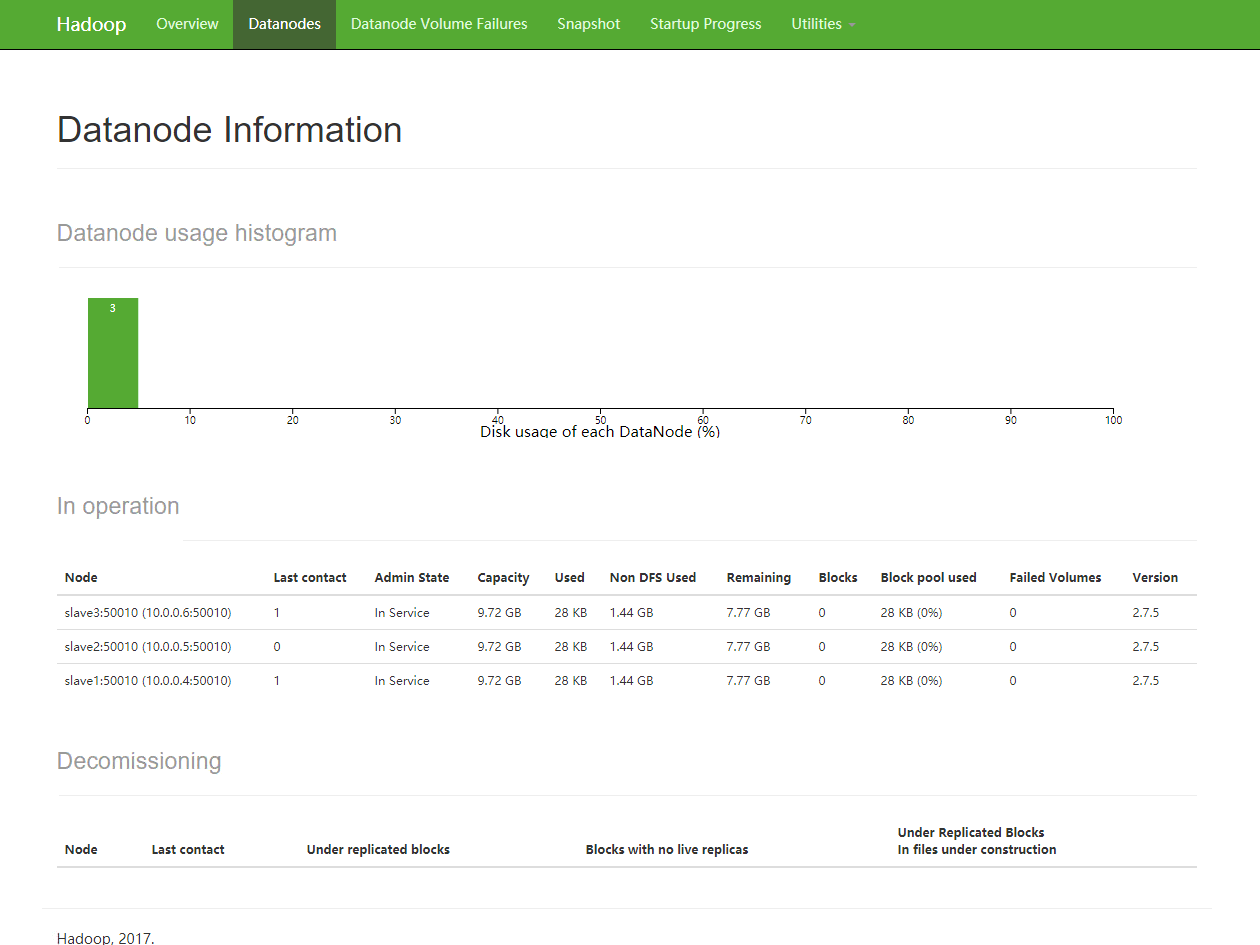
如果还想继续增加slave节点 只需要更改了slave节点的配置文件后启动就可以了。
HDFS的总容量会随着节点的增多而增多 拓展性是不是非常好呢。但是随着节点的增加又一个问题出现了 现在slave节点拓展到一千多台了 我该怎么启动这个集群呢?
集中式管理HDFS集群
Hadoop官方已经提供了一个批量启动和关闭HDFS集群的脚本了 而且以后用的更多的也是这些脚本。但是使用脚本之前 还需要做一些小配置。
配置ssh密钥认证
这一步配置master节点到其他slave节点的ssh密钥认证,其实就是master节点替你登陆到各slave节点启动DateNode了
此步骤只在master上进行
1 | ssh-keygen |
配置完成后可以ssh验证在master上是否可以免密码登陆所有slave节点了
配置slave节点
只有告诉了master有哪些slave节点 master才会帮助你启动或停止它们
修改/usr/local/hadoop/etc/hadoop/slaves如下
slave1
slave2
slave3
如果有localhost这条记录需要删掉 这样master节点就不会也被当作slave节点了
停止HDFS集群
因为HDFS集群已经是启动状态了 那就先试试停止它们吧
在master上执行1
stop-dfs.sh
再在各节点执行jps命令看看是不是NameNode和DataNode已经停止了呢
启动HDFS集群
停止使用的是
stop-dfs.sh命令 那启动就肯定是start-dfs.sh喽
1 | start-dfs.sh |
再用jps命令看看 是不是所有节点各自的服务都启动了呢
但是master上的进程好像不太一样 多了一个SecondaryNameNode,那么这个进程是做什么的呢
这个进程是帮助NameNode更好的工作 解决NameNode运行中可能出现的一些问题的 这也是NameNode容错的一种机制,具体作用可以查阅官方文档或搜索引擎。
接下来 就该看看这个HDFS该怎么用了吧 既然是一种分布式文件系统 那么它体现在哪里呢?
HDFS的文件操作
先简单介绍下HDFS文件的存储方式。将文件上传到HDFS中后 HDFS会将文件按照128M为一块进行分块存储。每一块又默认会复制三次 然后存放在三个不同的节点上。这样如果有某台机器宕机了 就还可以从其他节点拿到这一块文件,所以提供了文件冗余机制,并且HDFS还会将宕机节点丢失的块再复制一份到其他节点 保证每一块都存在三份。
HDFS的特性:文件分块 文件冗余 容易拓展
命令行管理HDFS中的文件
通过java程序或者其他语言的HDFS库就可以操作HDFS中的文件了。在Linux上也提供了一些命令去操作HDFS
1 | hadoop fs -ls / # 查看HDFS集群根目录的文件 应该是空的 |
HDFS是不允许对文件进行更改的 所以如果非要修改 只能把文件下载下来修改后再上传
Web界面浏览HDFS中的文件
为什么说是浏览呢 因为Web界面内是没法对文件进行操作的 只能看
浏览器打开:http://master:50070 首页的Summary中可以看到集群的状态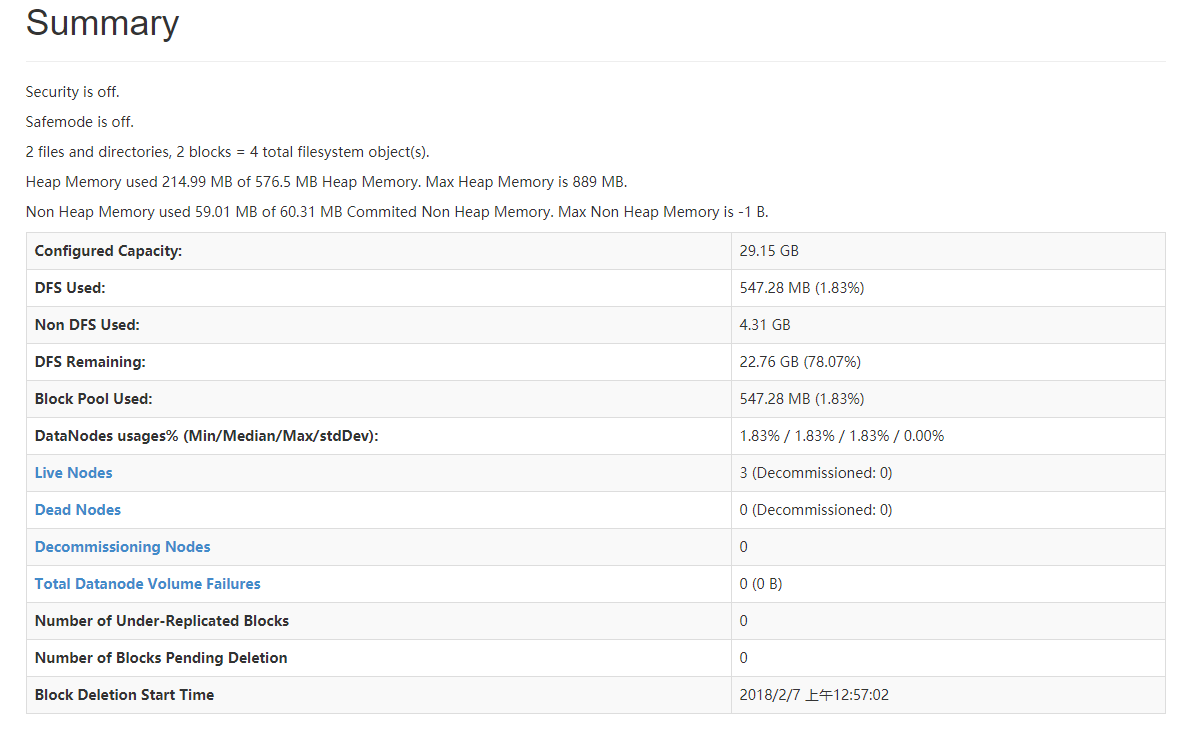
因为HDFS会把一个文件分块后复制三份存放在不同的节点上 jdk的大小是180多M 三倍大小差不多就是547M了
点击 Utilities 中的 Browse the file system 就可以看到集群中的文件了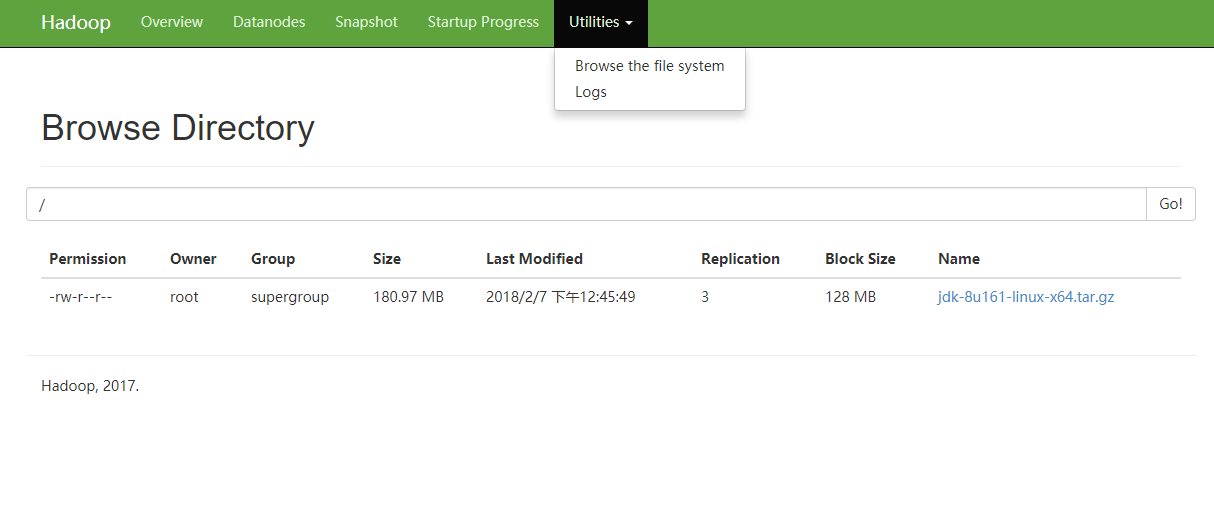
点击文件名称 可以查看文件的更多信息。
HDFS的块大小为128M, jdk文件自然被分成了两块 每一块都存放在了三个节点上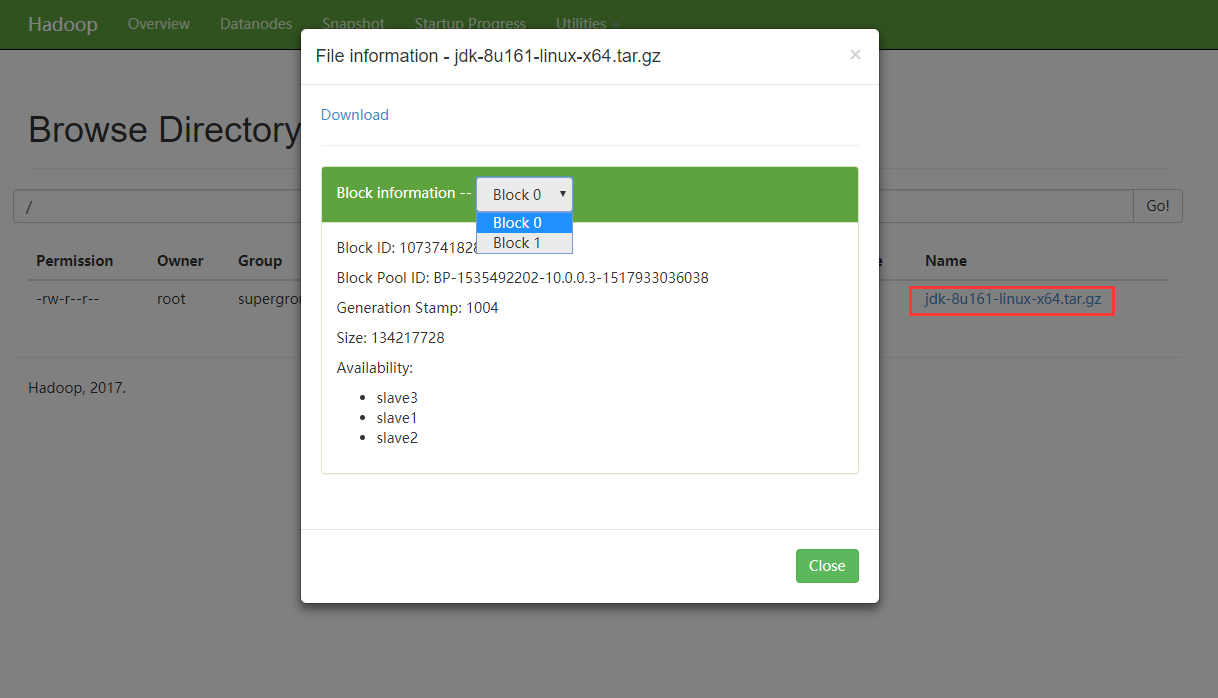
HDFS的配置
默认HDFS会将文件复制三份 但是你觉得数据并不是那么重要 复制两份就满足数据冗余的需求了,那么如何更改这个配置呢
查阅官方文档
学习一个技术最好的方法就是查阅它的官方文档,官方文档永远是第一手资料。
打开Hadoop的官方首页:http://hadoop.apache.org/
然后左侧栏点开 Documentation 找到自己的版本:http://hadoop.apache.org/docs/r2.7.5/
左侧栏的最下方有个Configuration 既然是对HDFS进行配置 那肯定是看 hdfs-default.xml 的了
点开后可以看到茫茫多的配置 这些配置都是HDFS的默认配置 只用修改相应的值就可以了。既然是复制 那就看看和复制有关的配置,在网页中搜索 "replication"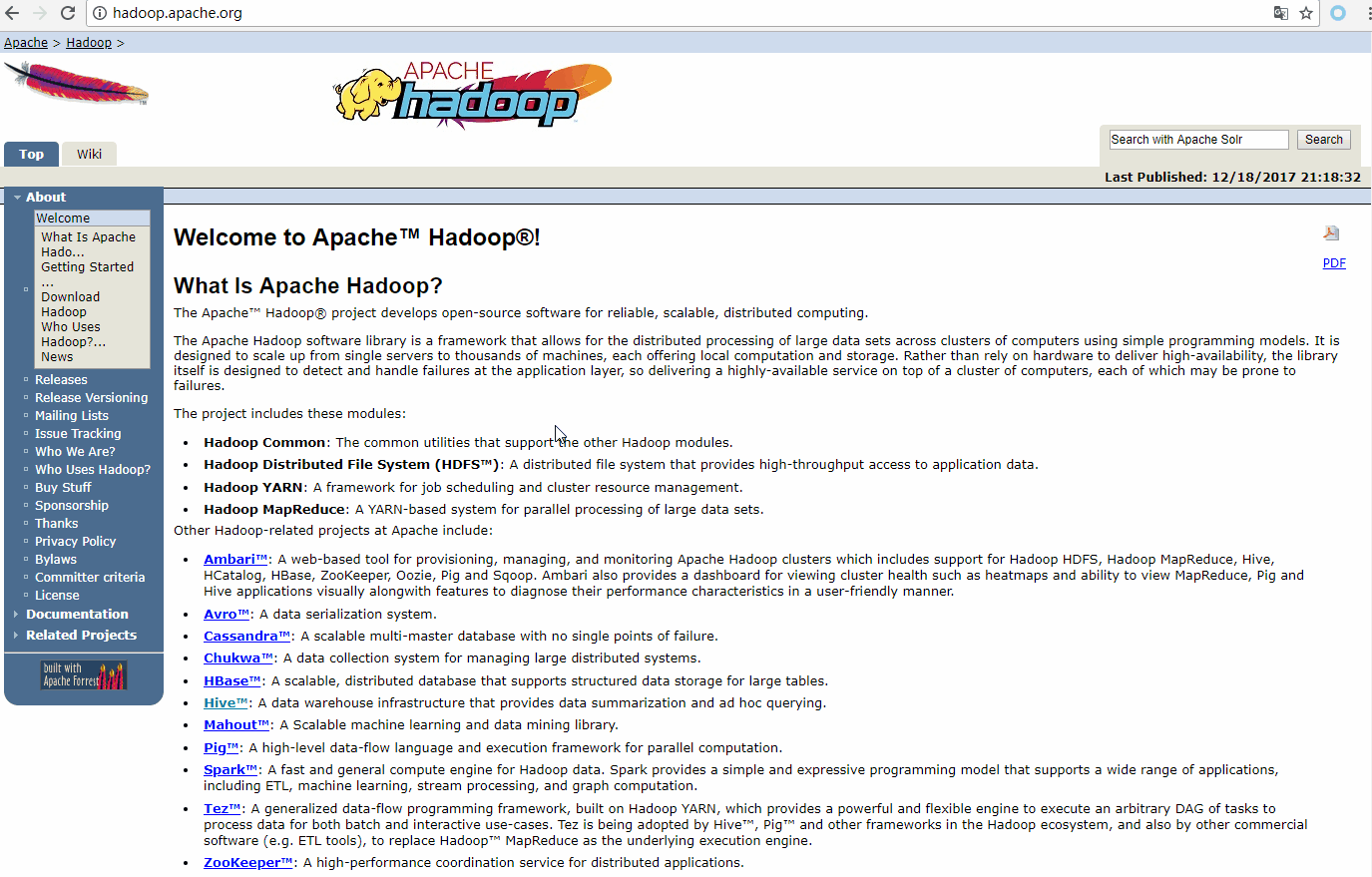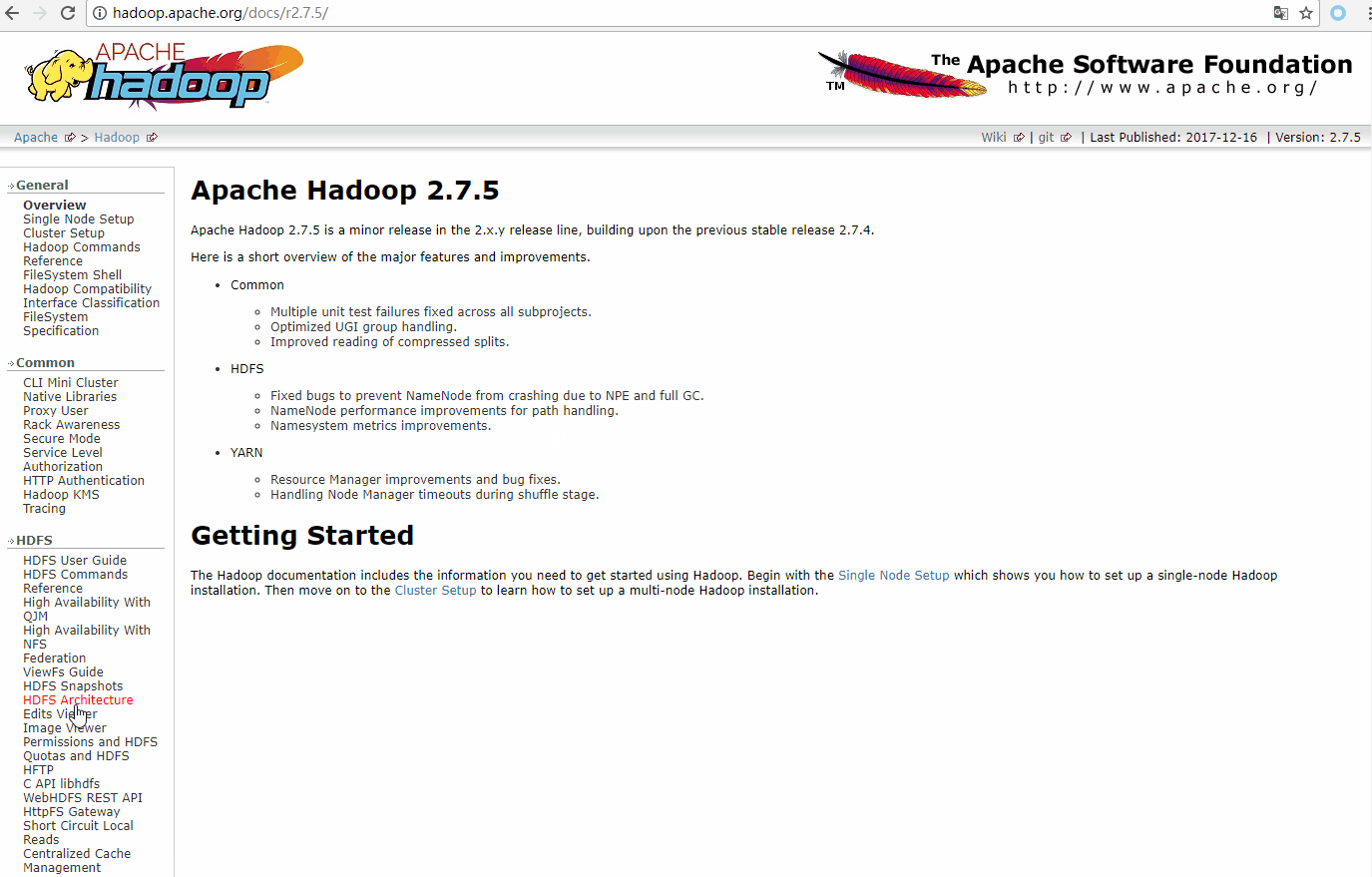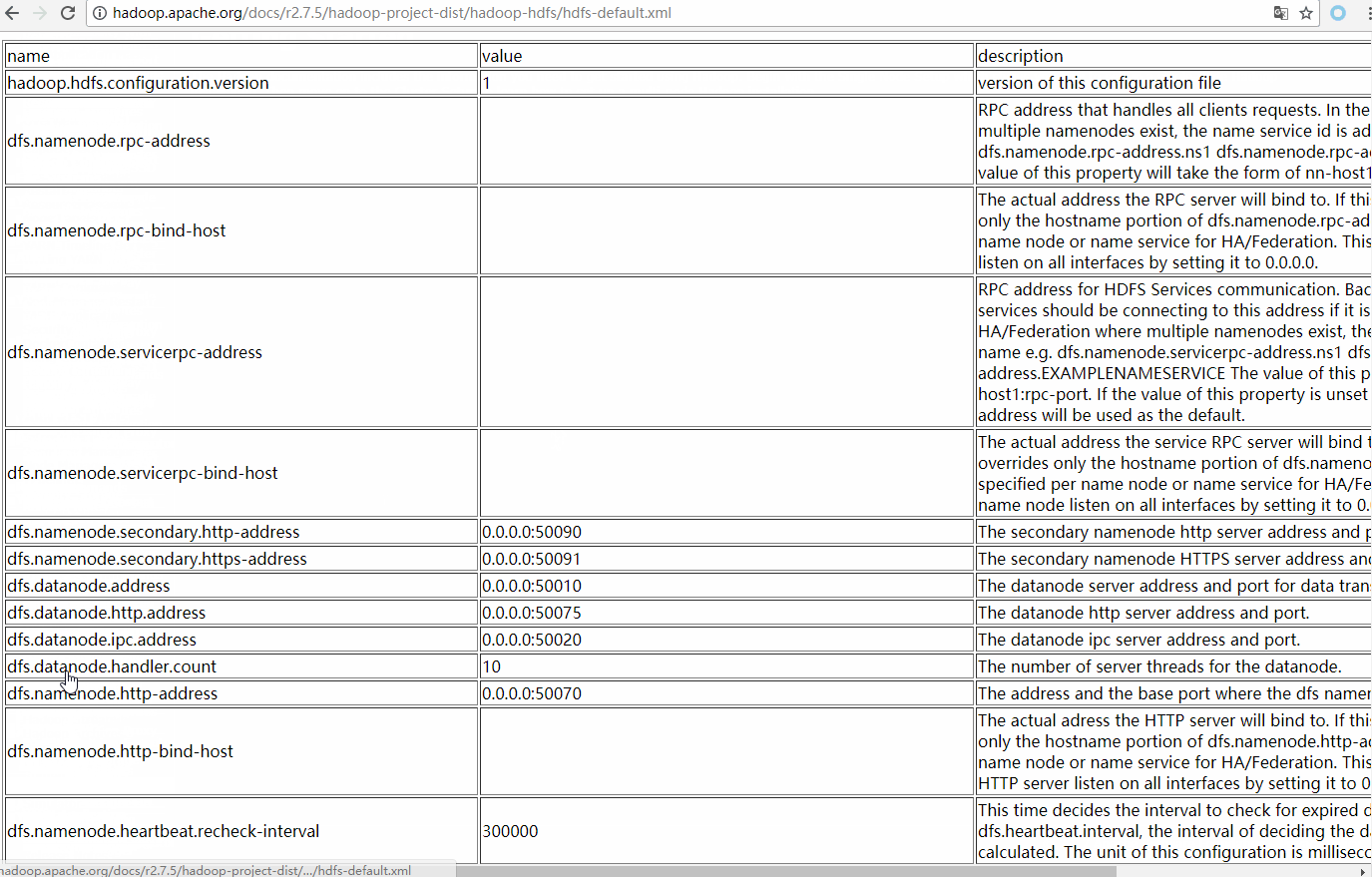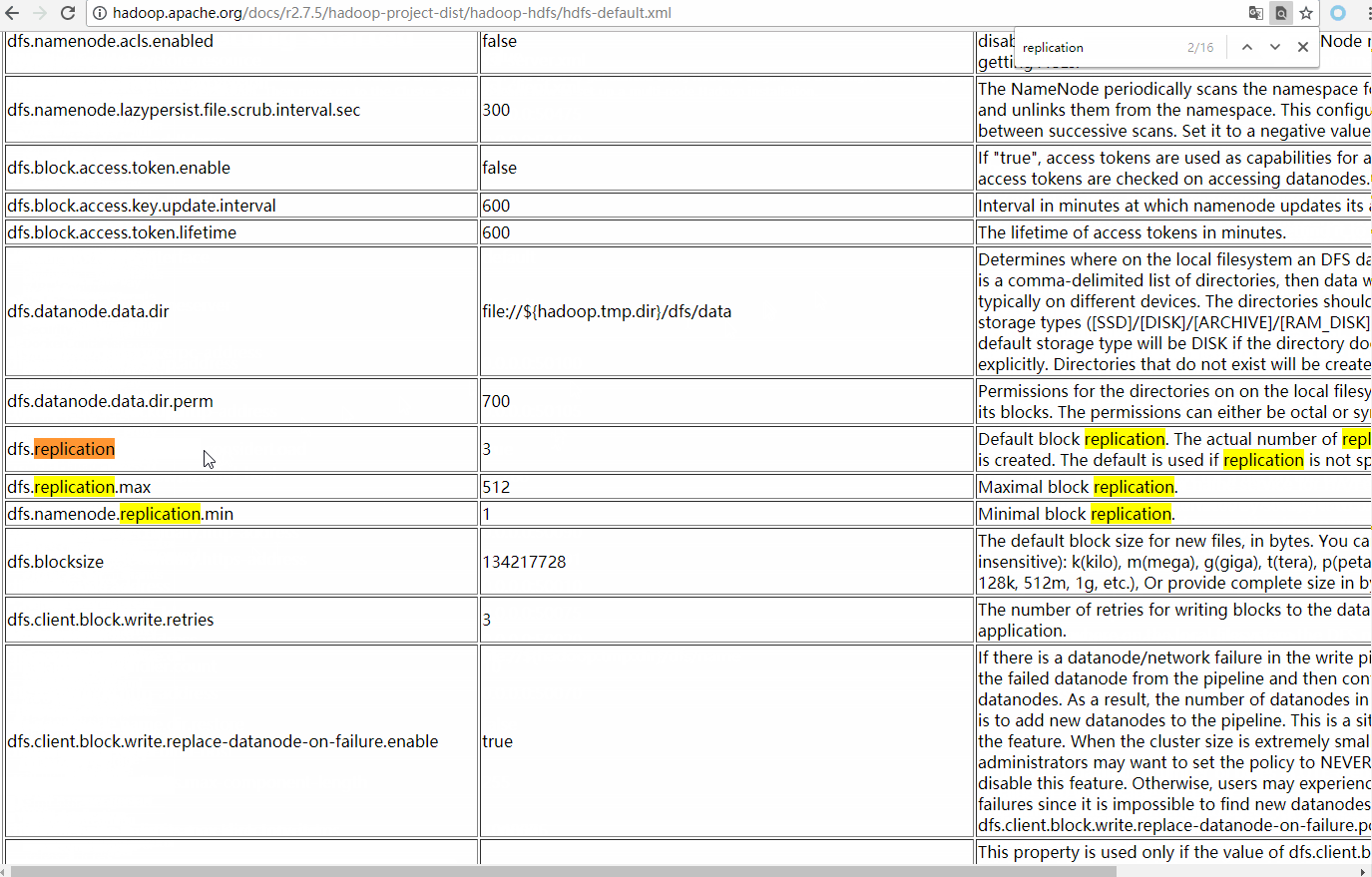
dfs.replication 就是我们要更改的目标了
修改 hdfs-site.xm
只需要修改master节点的
hdfs-site.xml就可以了
修改为如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
保存退出后重启集群1
2stop-dfs.sh
start-dfs.sh
接下来再测试下是否文件只复制2份了 上传一个新文件到HDFS中1
hadoop fs -put /tmp/hadoop-2.7.5.tar.gz /
浏览器查看文件信息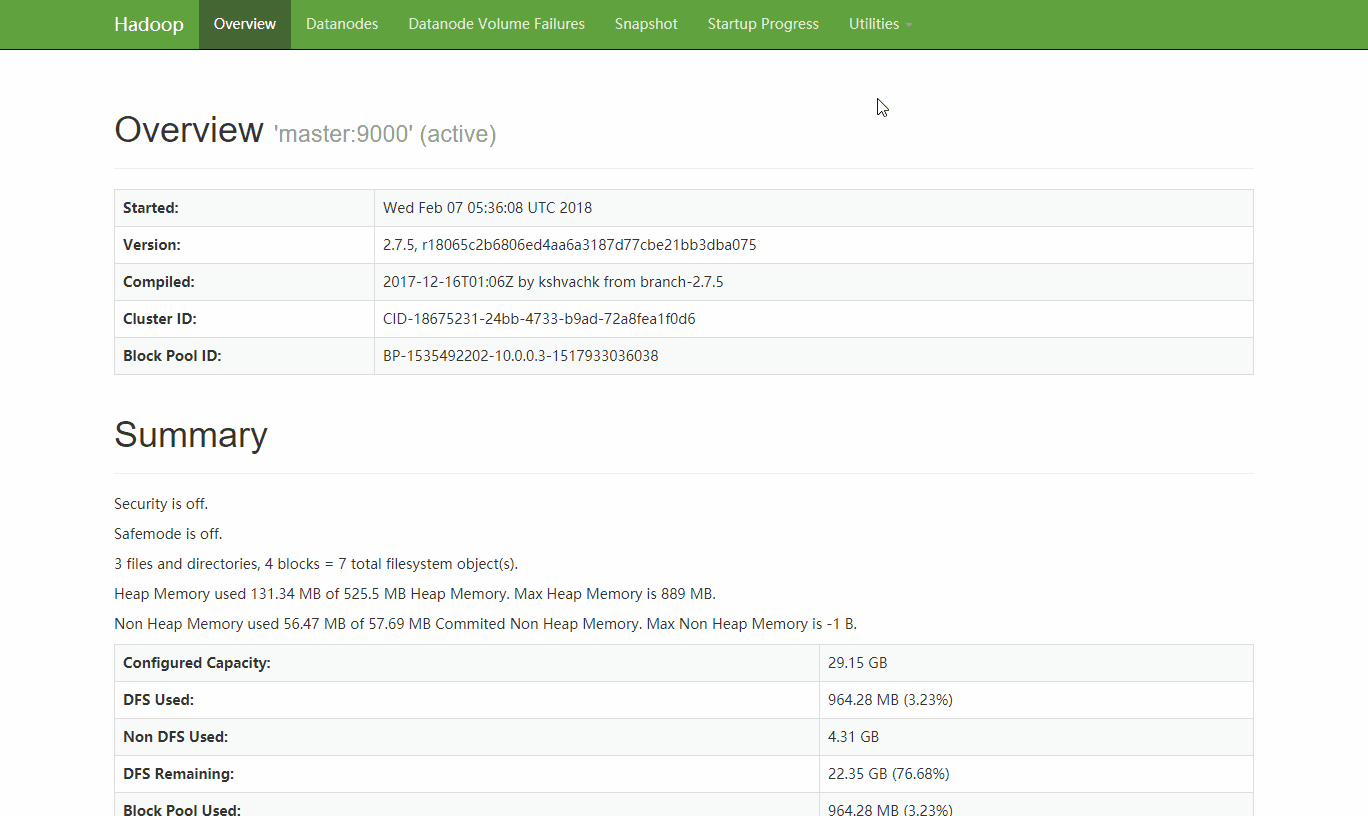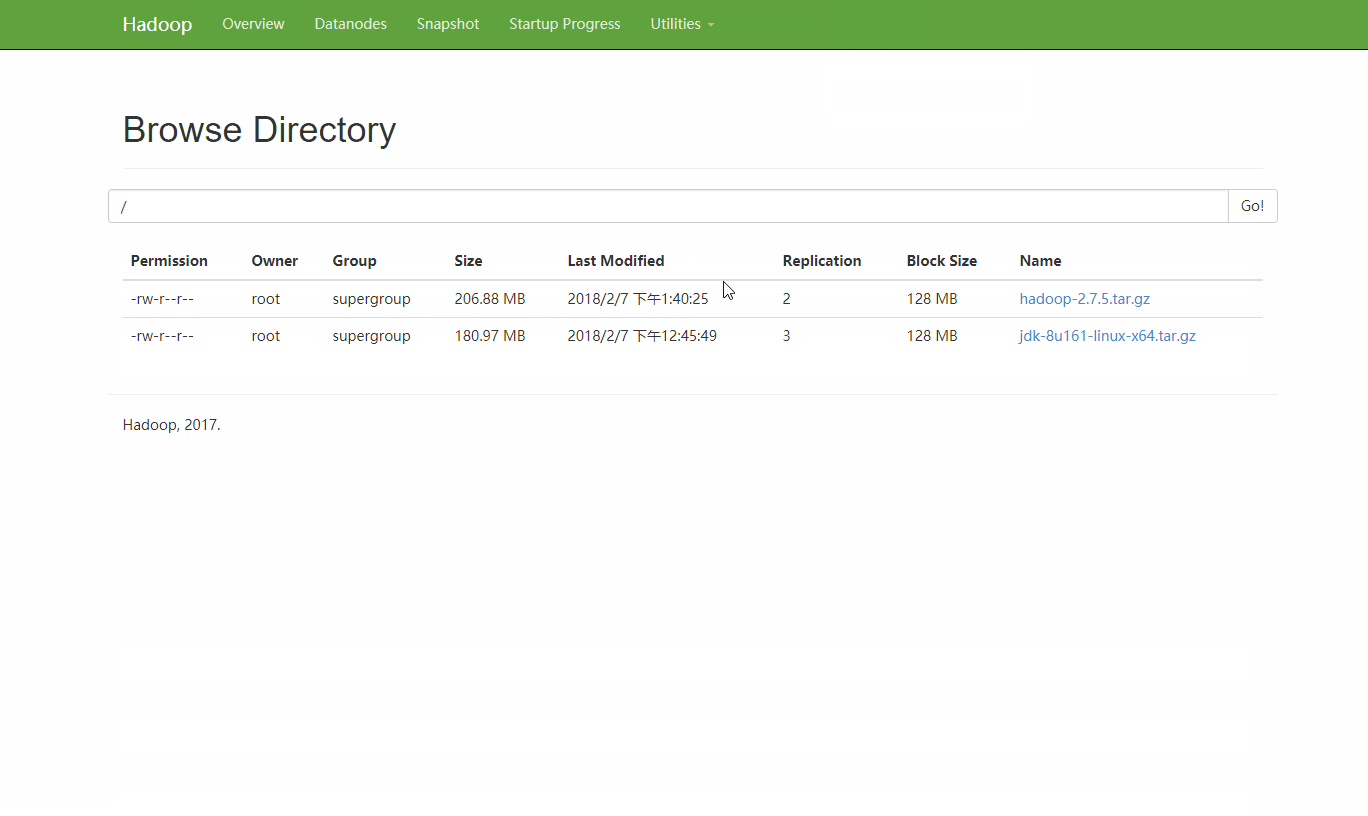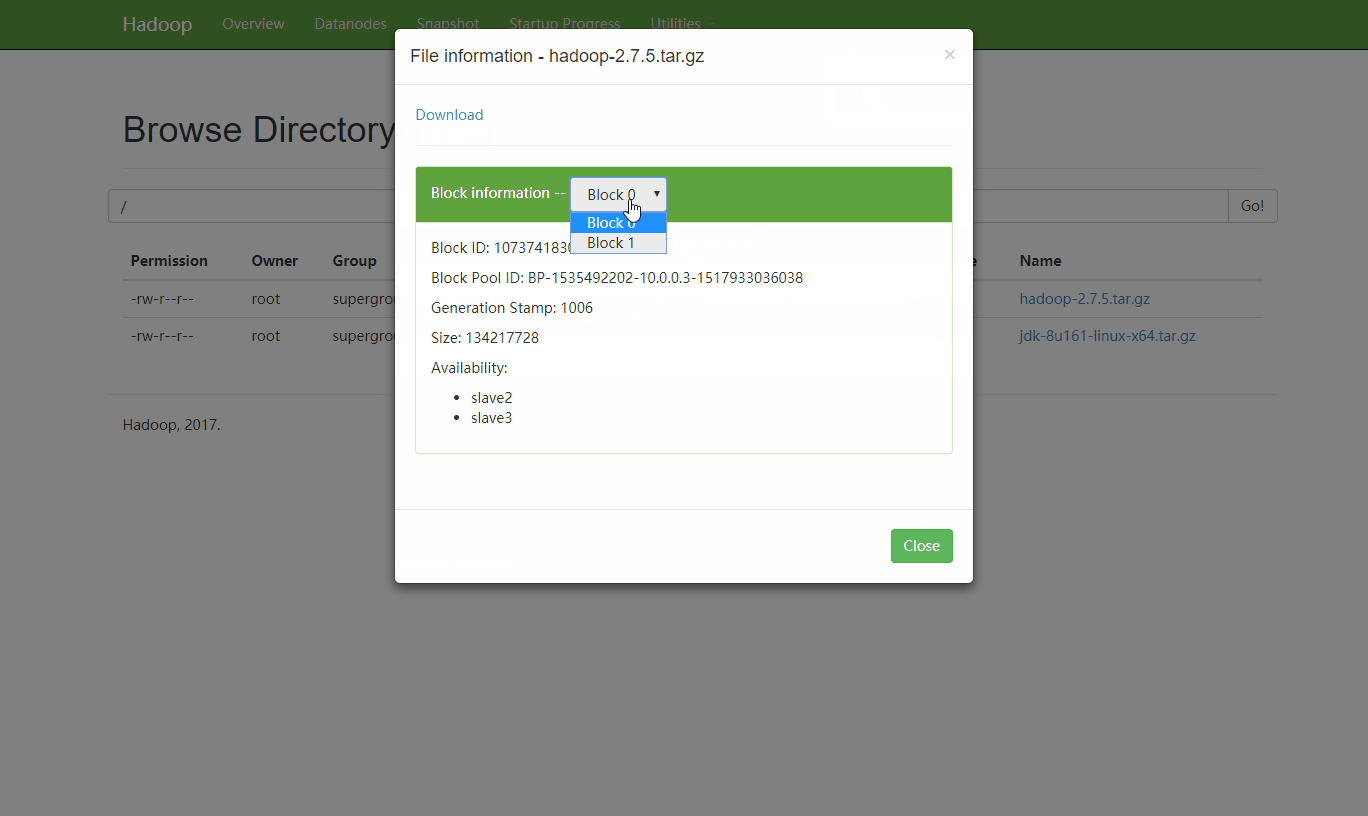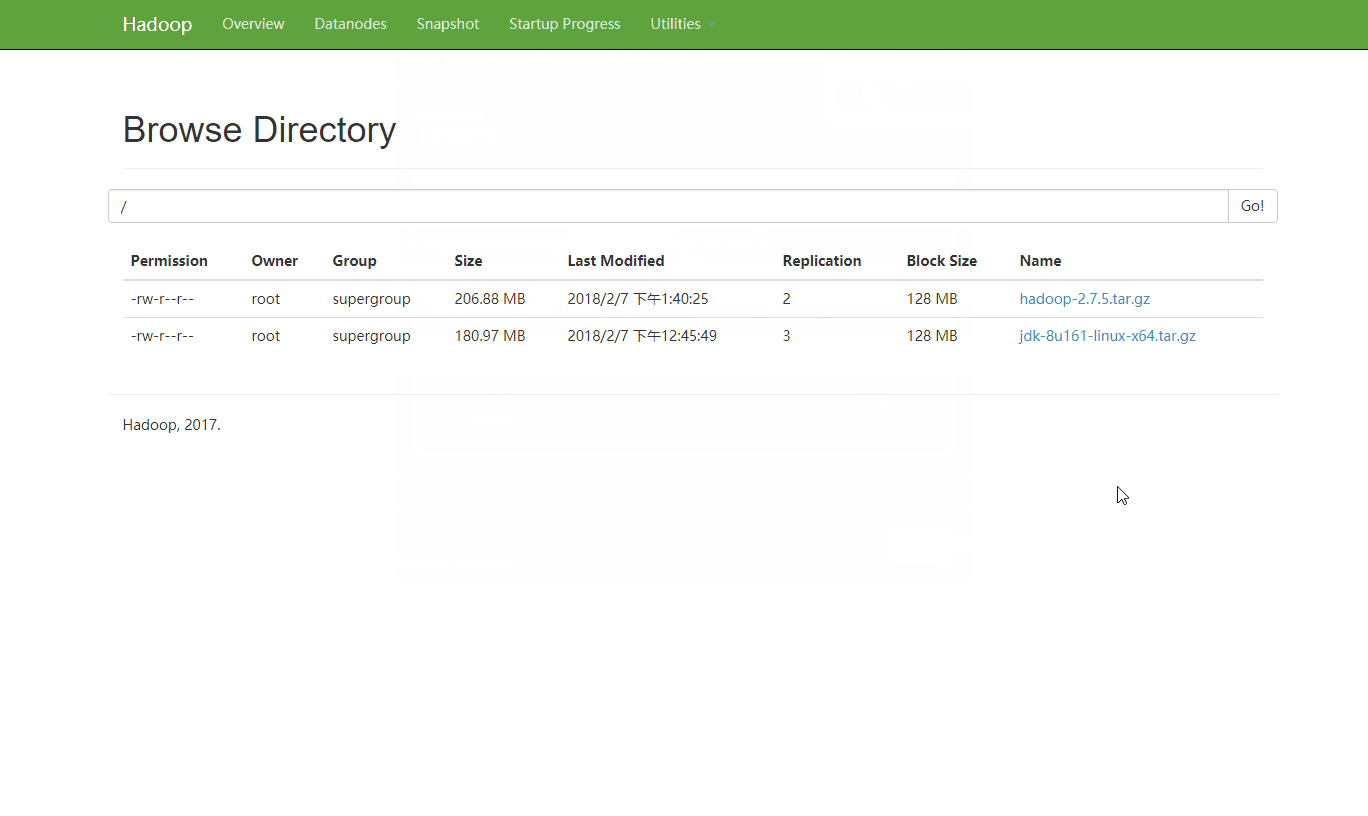
可以看到 hadoop-2.7.5.tar.gz 只被复制了2份,并且文件的每一份都尽量平均的分散在集群的不同slave中。block0存放在slave2和slave3上,block1存放在slave1和slave3上,那么如果slave1宕机了 HDFS会做哪些操作呢
slave1宕机模拟
只要slave1和master不能正常通信就可以了,可以停掉slave1的datanode服务 或者开启slave1的防火墙阻止通信都可以。
master会定期检测slave的状况 只有发现slave挂了后才会将缺少的文件再复制一份到其他节点。这个默认周期是300000毫秒 也就是5分钟。
如果不想等待这么长时间 可以修改hdfs-site.xml,配置dfs.namenode.heartbeat.recheck-interval的值为10000也就是10秒
在slave1上运行:1
hadoop-daemon.sh stop datanode
过一阵子刷新浏览器 可以看到slave1已经离线了,并且又在slave2上复制了一份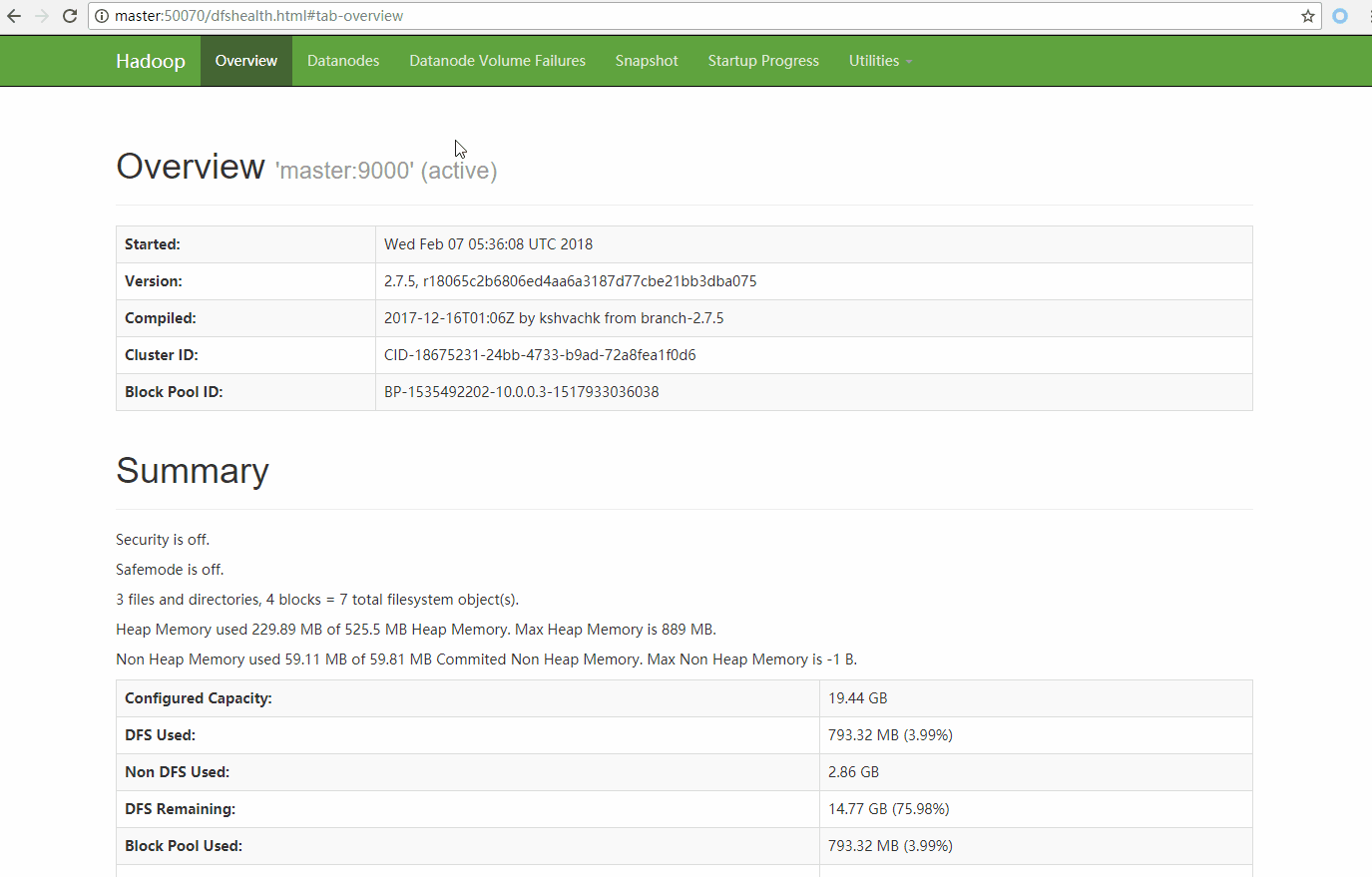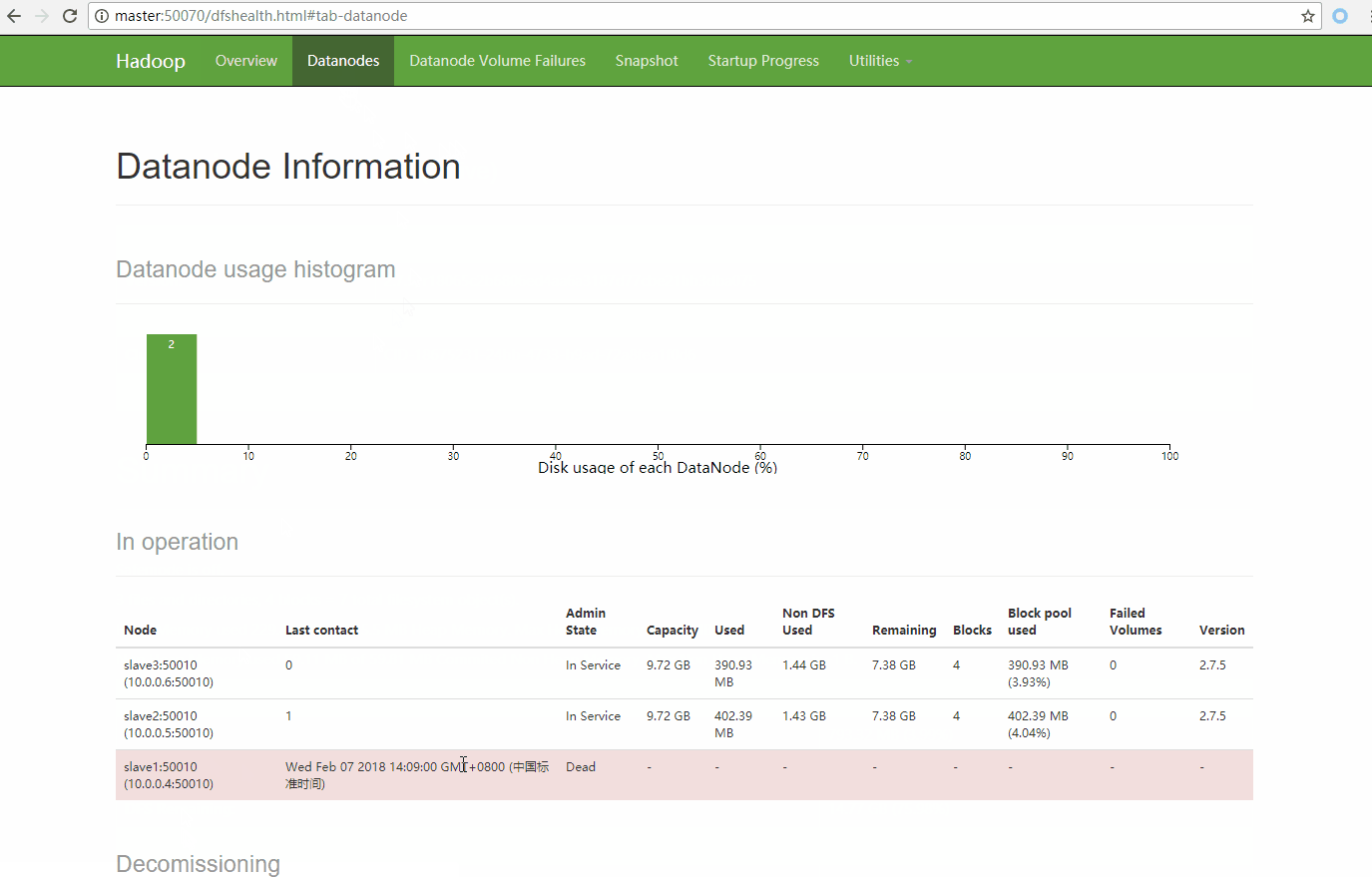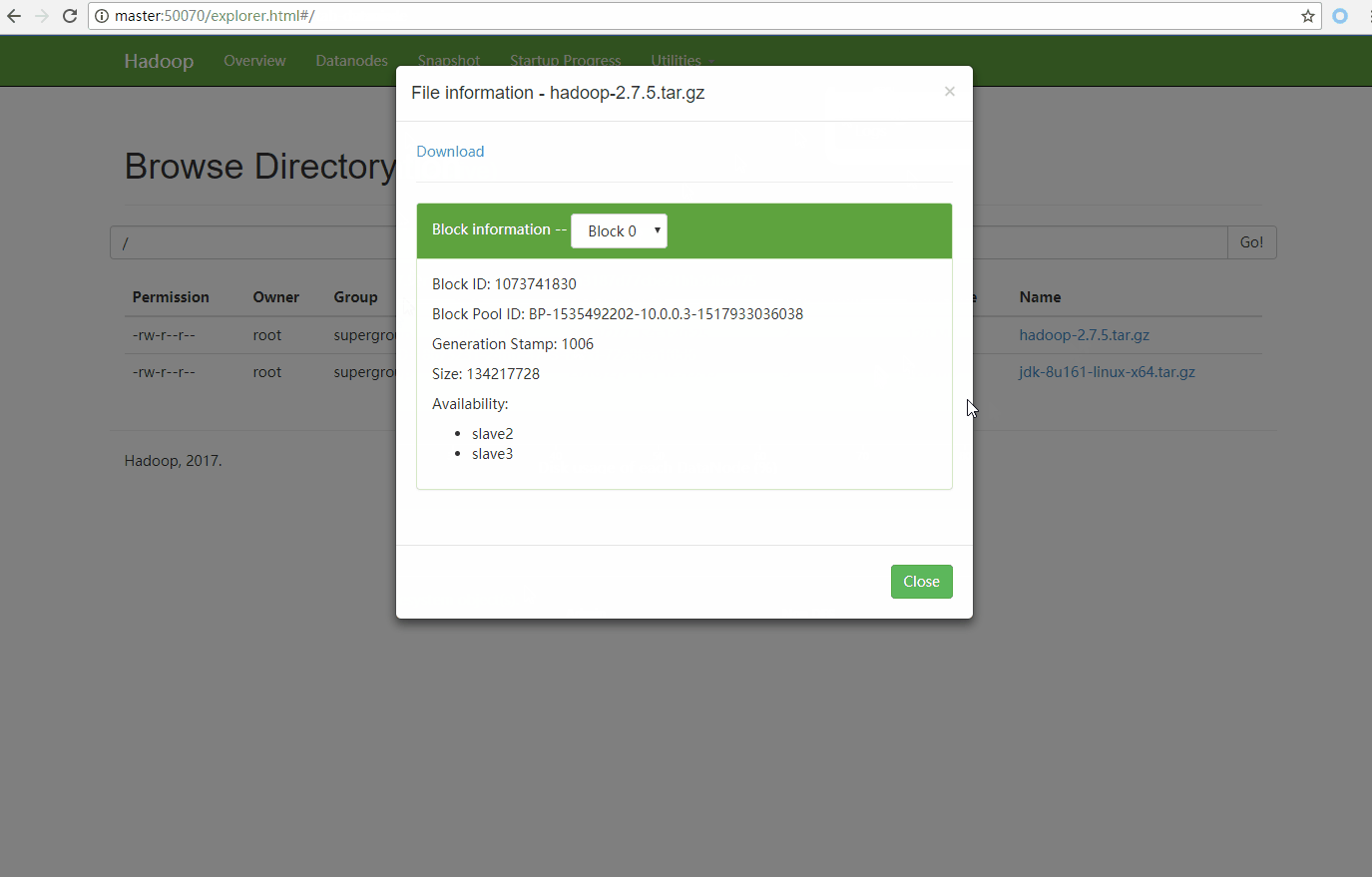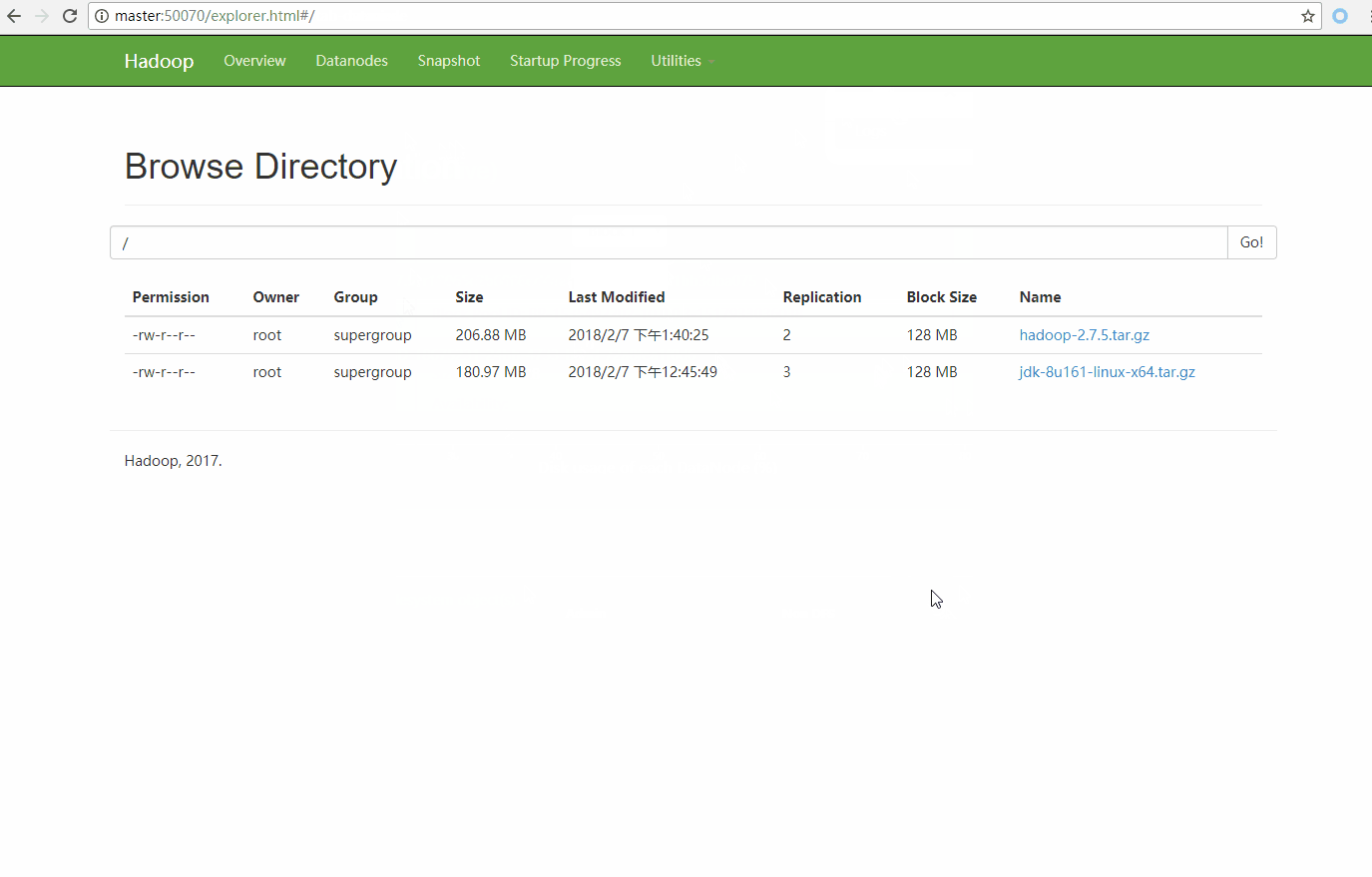
测试完后记得重新启动 slave11
hadoop-daemon.sh start datanode
刷新浏览器可以看到 slave1又上线了
修改数据存储路径
HDFS文件的数据块最终还是要真实存在硬盘上的,HDFS的默认数据存放路径为
/tmp/下 这显然不是一个好主意
NameNode的数据存储位置定义在 dfs.namenode.name.dir 默认值为 file://${hadoop.tmp.dir}/dfs/name
DataNode的数据存储位置定义在 dfs.datanode.data.dir 默认值为 file://${hadoop.tmp.dir}/dfs/data
我们将数据目录修改到 /data/dfs 下
master节点配置如下:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/dfs/name</value>
</property>
slave节点全部配置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/dfs/data</value>
</property>
以下操作在master上进行1
2
3stop-dfs.sh # 停止集群
mkdir -p /data/dfs/name # 创建相应目录
hadoop namenode -format # 重新格式化
接下来在slave节点上创建目录1
mkdir -p /data/dfs/data
然后master上重新启动HDFS集群吧1
start-dfs.sh
HDFS的内容就先到这里吧 更多的配置项在以后用到的时候慢慢学习和了解 遇到不懂得地方记得查阅官方文档哦
YARN资源调度器
YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算模型中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算模型作为一个应用程序运行在YARN系统之上,通过YARN来管理资源。如果你的应用程序也需要借助YARN的资源管理功能,你也可以实现YARN提供的编程API,将你的应用程序运行于YARN之上,将资源的分配与回收统一交给YARN去管理,可以大大简化资源管理功能的开发。当前,也有很多应用程序已经可以构建于YARN之上,如Storm、Spark等计算模型。
YARN的基本概念
有了HDFS的基本概念 理解YARN也比较简单了 HDFS是将文件分布式存储在不同的slave节点上,而YARN是将任务拆分到不同的计算节点上。
Hadoop第一代中是没有YARN的概念的,Hadoop第二代开始专门将资源调度抽取出来了 所以才有了YARN。Hadoop第一代中 只有HDFS和一个MapReduce计算模型。但是MapReduce发展中发现了一些局限性,比如不支持内存模型、流式模型等计算模型。在Hadoop第二代的时候对这个问题进行了改进 在HDFS之上抽象出了一个资源调度模型,这个资源调度模型就是YARN(Yet Another Resource Negotiator)。
YARN对集群的内存、CPU资源进行调度,将计算任务按照算法分发到集群节点。有了这个抽象层 就可以在之上能跑的就不只有MapReduce了,还有各种各样的计算模型,比如Spark、Storm等。YARN只做调度 不参与计算。
YARN的master上运行ResourceManager,slave上运行NodeManager。YARN和HDFS是低耦合的,可以部署在一个集群中 也可以分开部署在两个集群中。把NodeManager和DataNode部署在同一个节点上,可以使NodeManager读取HDFS的效率更高 所以一般都将NodeManager和DataNode部署在一起。
而ResourceManager和NameNode都比较吃内存,所以最好分开部署。实验中将ResourceManager和NameNode部署到了一起。
用户编写好计算的任务程序 然后去请求ResourceManager,ResourceManager将用户的任务拆分,然后分发到NodeManager节点进行计算,计算节点再从HDFS中获取数据。下面就看看YARN如何配置和启动。
配置YARN集群
修改YARN的配置文件
修改所有节点的yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
yarn.resourcemanager.hostname 指明ResourceManager在master上 只修改这一个 YARN集群就可以起来了。下面两个配置是NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。
启动YARN集群
YARN的启动和HDFS的启动类似 可以单个启动 也可以集群化方式启动
单独启动YARN节点
master节点上执行1
2yarn-daemon.sh start resourcemanager # 启动ResourceManager
yarn-daemon.sh stop resourcemanager # 停止ResourceManager
slave节点上执行1
2yarn-daemon.sh start nodemanager # 启动NodeManager
yarn-daemon.sh stop nodemanager # 停止NodeManager
集群化启动
master节点上执行1
2start-yarn.sh # 启动整个YARN集群
stop-yarn.sh # 停止整个YARN集群
Web界面查看集群状态
ResourceManager启动后 会在8088端口提供一个web界面,通过这个web界面可以看到节点状态,任务运行状态等
浏览器访问:http://master:8088/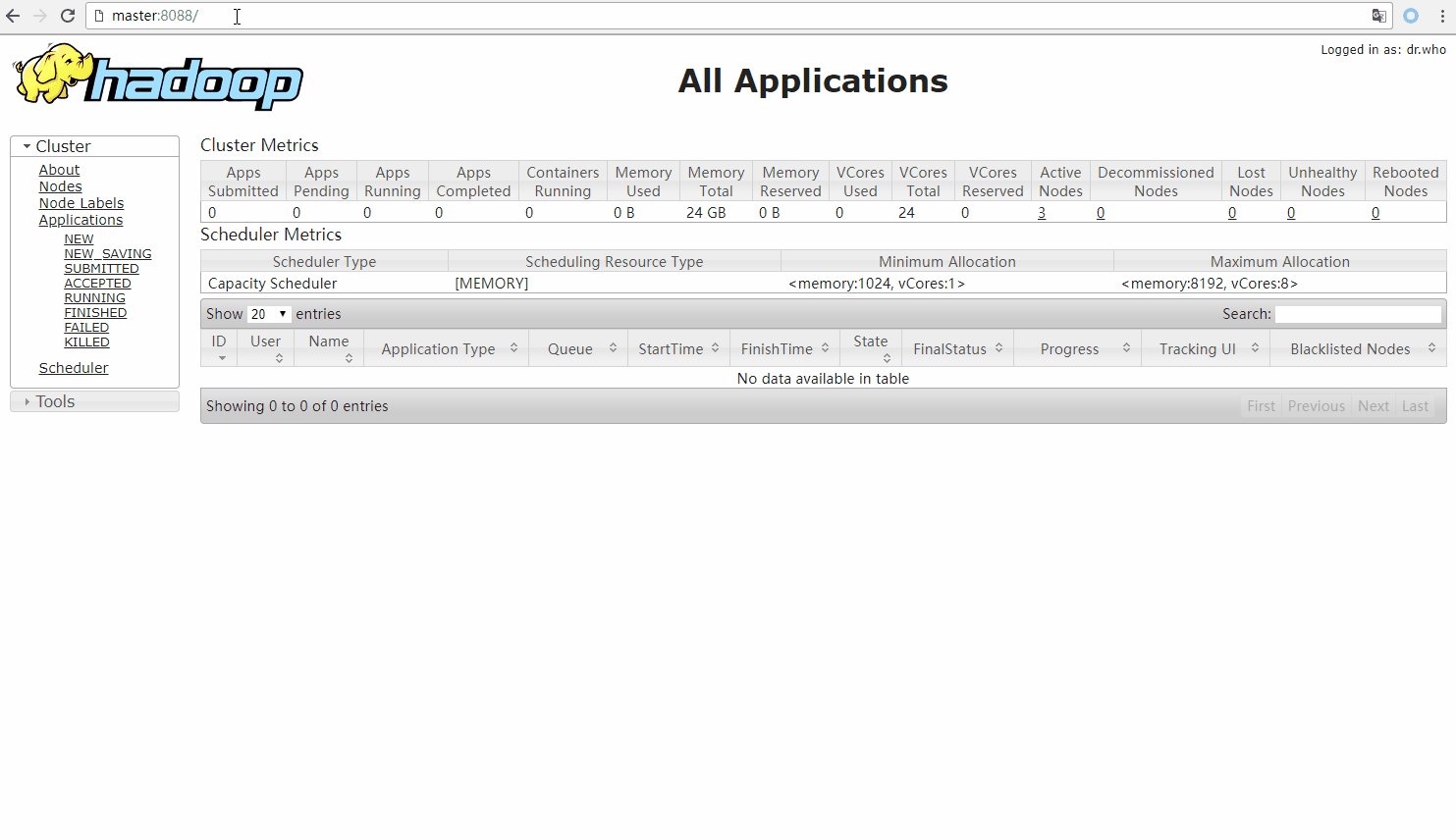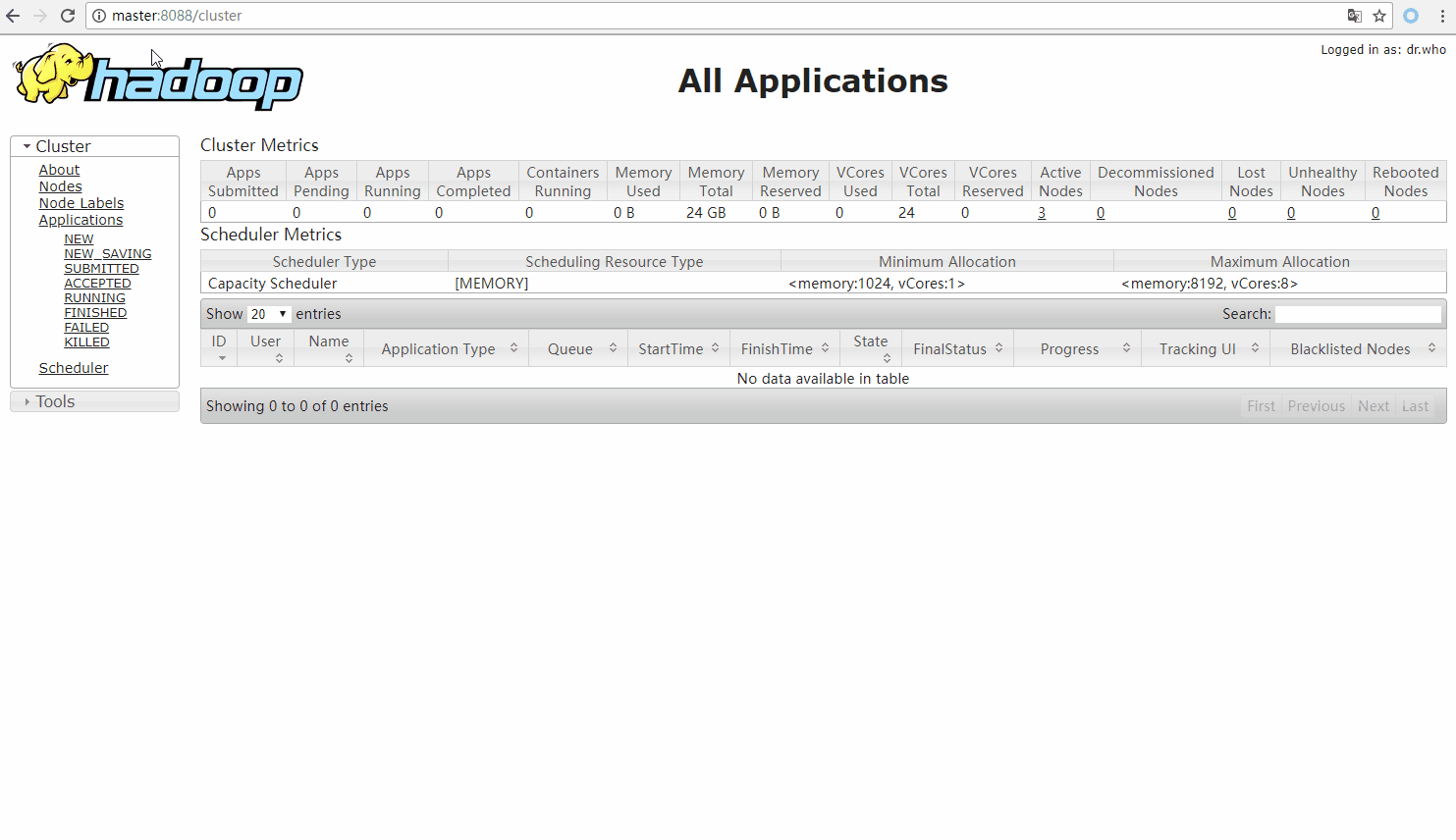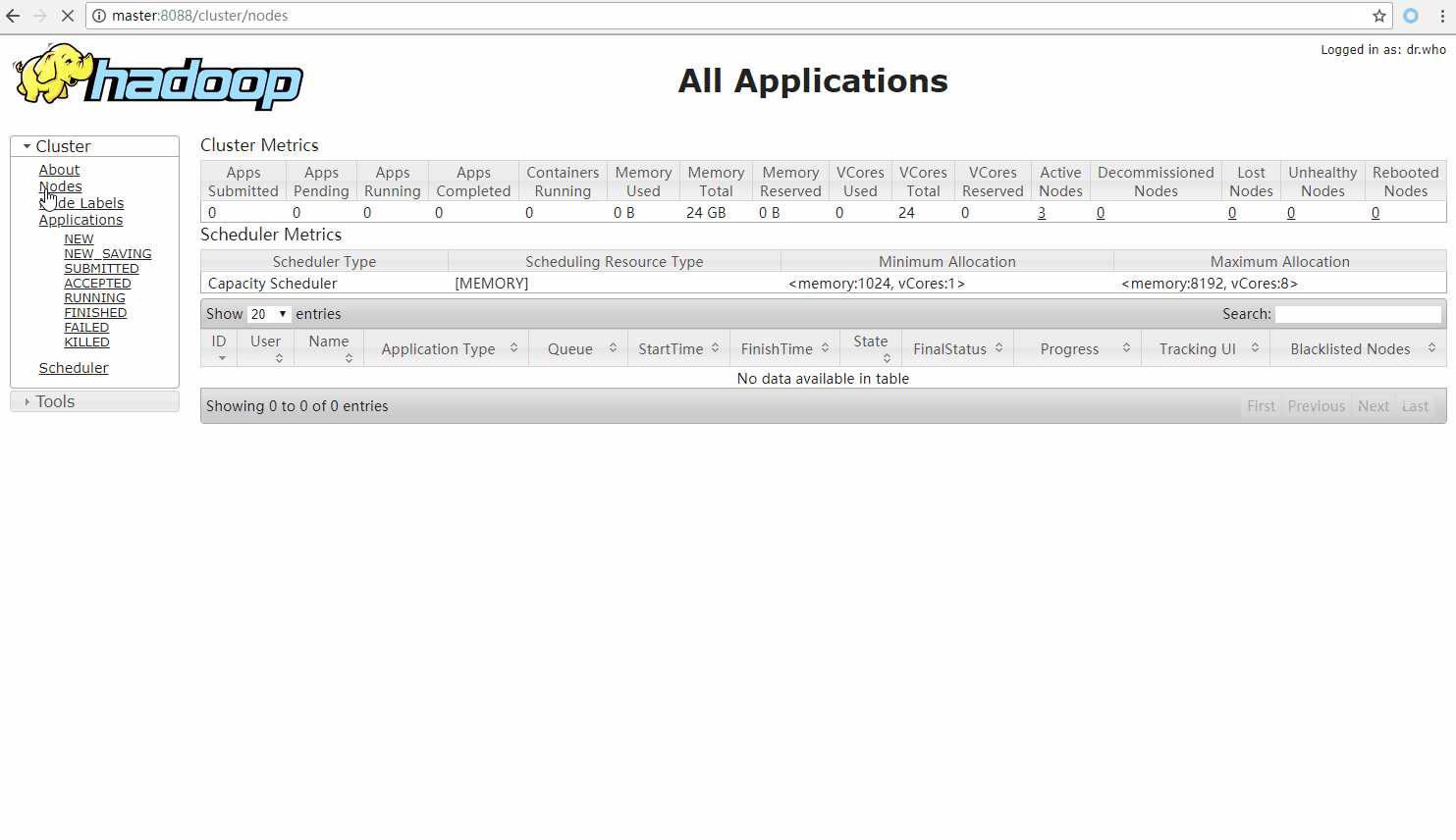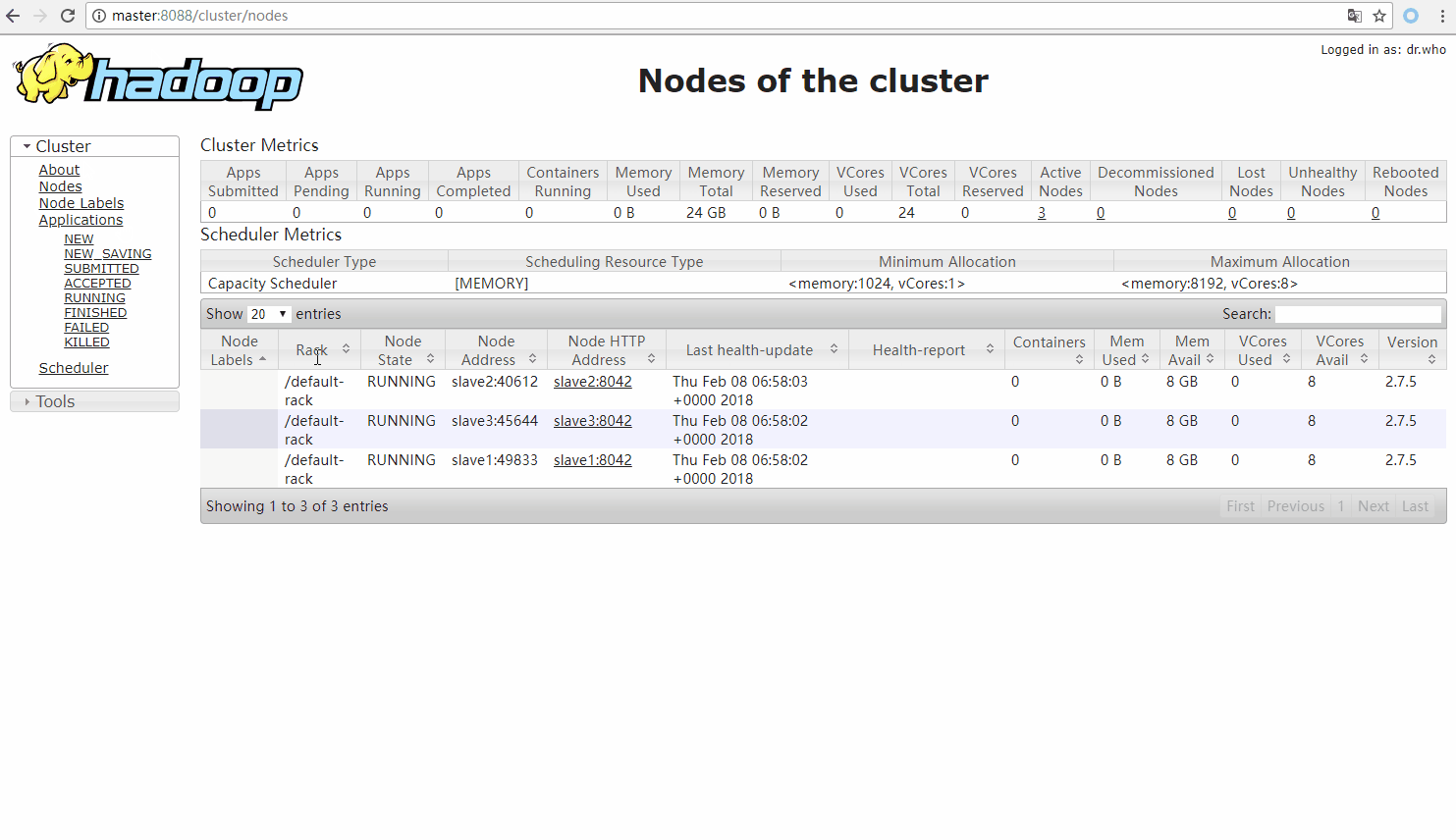
YARN起来后怎么测试效果呢 那就跑个MapReduce计算看看吧
MapReduce计算模型
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。
Hadoop的设计思想也来源自Google的几篇论文,MapReduce的论文里提到 MapReduce的灵感来自于函数式语言Lisp中的内置函数map和reduce。
对于熟悉Python语言的人 应该都知道Python的两个内置函数map和reduce,如果对着两个函数的运用也比较熟练的话,MapReduce计算模型也很容易理解了。
下面就来看看利用MapReduce思想 是怎么解决数据处理中的问题的
第一个MapReduce程序
一个很简单的例子 统计一个文本文件中每个单词出现的次数。首先 先配置好MapReduce吧
修改配置文件
mapred-site.xml是MapReduce计算模型的配置文件。
MapReduce和YARN也是低耦合的,跑MapReduce计算并不一定需要YARN,当然YARN上面并不只能跑MapReduce。
这里就使用YARN来调度MapReduce使用的计算资源。
修改master节点的mapred-site.xml文件
mapred-site.xml文件不存在 所以需要先复制一份1
2cp /usr/local/hadoop/etc/hadoop/{mapred-site.xml.template,mapred-site.xml}
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapreduce.framework.name 指定了MapReduce在YARN这个框架上跑,如果不配置就默认在本地单机上跑。
运行wordcount任务
/usr/local/hadoop/share/hadoop/mapreduce中有一个hadoop-mapreduce-examples-2.7.5.jar
里面包含了一些官方给出里例子wordcount就是其中的一个
创建测试文本
新建一个文件tmp.txt 然后写入以下内容:
hello world
hello python
hello java
hello java
hi python
hi c
hi c++
hi lua
hello lua
为了效果明显点 可以将这些内容多次写入到test.txt文件1
while :; do cat tmp.txt >> test.txt ; done
这里已经获得了一个30M大小的文件了
root@slave1:~# ls -lh test.txt
-rw-r--r-- 1 root root 30M Feb 8 08:34 test.txt
上传到HDFS中1
hadoop fs -put test.txt /
开始测试吧!1
2cd /usr/local/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.5.jar wordcount /test.txt /testout
简单讲解下这条命令的意思 -jar 是运行这个jar包,wordcount是运行jar包中 wordcount这个类 /test.txt 是输入文件 /testout 是输出目录,一定要注意 /testout 一定要不存在才行。
现在可以看到命令的输出
Web界面也可以看到任务的运行状态
点击任务的ID 就可以看到这个任务是跑在了哪些节点上哦。因为30M对于Hadoop来说简直太小了 所以只分配了两个节点就够了。这个任务中 可以看到两个Maps进程都跑在slave1上 一个Reduces进程跑在slave3上
PS: 任务可以在任何节点跑 但是想要使用YARN进行资源调度的话 也需要修改相应节点的mapred-site.xml文件,否则就成了本地单机版的MapReduce了。
ResourceManager节点重启后 所有的任务记录也都会丢失哦。
查看任务结果
还记得输出目录 /testout 吗 结果就在那里
先看一看/testout下有什么吧
root@master:~# hadoop fs -ls /testout
Found 2 items
-rw-r--r-- 2 root supergroup 0 2018-02-08 08:53 /testout/_SUCCESS
-rw-r--r-- 2 root supergroup 95 2018-02-08 08:53 /testout/part-r-00000
_SUCCESS是表示这个任务执行成功
part-r-00000 就是结果了 如果是个结果集的话 还会有part-r-00001、part-r-00002 …
那就看看这个文件的内容吧
root@master:~# hadoop fs -cat /testout/part-r-00000
c 360944
c++ 360944
hello 1804720
hi 1443776
java 721888
lua 721888
python 721888
world 360944
可以看到每一个单词出现的次数都被统计出来了,那么它是怎么实现的呢?
MapReduce的运行原理
MapReduce的内部工作方式是怎样的呢?它是怎么解决单词统计这个任务的呢?
Map 和 Reduce
举个简单的例子:
顾客想知道他经常去的图书馆里有多少本书,于是找到了老板。
“Hi! 老板 我想知道你的图书馆里有多少本书”
“好嘞 我让手下去数一数”
一共有二十个书架 领导分配了十个人去数,第一个人数1,2书架,第二个人数3,4书架以此类推
等数完后将结果交给另外一个人去汇总 把每个书架的结果累加起来
汇总完后 将结果给了老板后 老板告诉顾客有多少本书
这个例子中 顾客 就是开发者
老板呢 就像是YARN进行工作调度
所有的书就像是HDFS中存储的数据
工人的工作就是所谓的Map了 而汇总统计的那个人做的工作 就是Reduce
Map呢 就是将数据整理 归类 将复杂的数据变得简单有结构
Reduce呢 就是拿到同类的数据后进行处理 计算
再讲一个做水果沙拉的例子:
一堆不同种类的水果 要做成水果沙拉
挑出一个 是香蕉 好 切成块
挑出一个 是苹果 好 切成块
挑出一个 是梨 好 切成块
挑完也切完了 好 混在一起做成水果沙拉
挑和切的动作 就可以看作Map,最后将所有的水果块做成水果沙拉 就可以看作是Reduce的过程了
Map和Reduce 只是一种思想 并不局限于一种固定的解决问题的模式 如何玩转这种思想 得到自己想要的结果 就是一门艺术了。这就是我所理解的MapReduce。
wordcount程序的实现
回到正题 看看这个自带的wordcount程序的实现是怎么样的呢
1. 输入(input) 将文档输入到Map进程
hello world
hello python
hello java
hello java
2. 拆分(split) 将每一行都转为key-value形式
0 - hello world
1 - hello python
2 - hello java
3 - hello java
3. 映射(map)将每一行的每一个单词都形成一个新的key-value对
hello 1
world 1
hello 1
python 1
hello 1
java 1
hello 1
java 1
4. 派发(shuffle)将key相同的扔到一起去
hello 1 1 1 1
world 1
python 1
java 1 1
5. 缩减(reduce)将同一个key的结果相加起来
hello 4
world 1
python 1
java 2
6. 输出(output)将缩减之后的结果输出
自己写一个MapReduce程序
Map和Reduce的过程 是可以用户自定义的 那我们就自己实现一个统计字数的程序仍到Hadoop上跑吧
不会写java不怕hadoop-streaming-2.7.5.jar这个包 提供了使用其他语言来写MapReduce程序的方法,这里用Python来实现。
Map
编写 mapper.py 文件
1 | #!/usr/bin/env python |
1. 从标准输入获取数据 然后按行读取
hello world
2. 然后使用空白字符分割为一个列表
["hello","world"]
3. 将列表中的每一个元素都转为key-value,并且写入到标准输出
hello 1
world 1
4. 继续从标准输入读取下一行 直到结束
Reduce
编写 reducer.py 文件
1 | #!/usr/bin/env python |
1. 创建一个保存结果的字典 result
2. 从标准输入中读取一行
hello 1
3. 使用空白字符分割为一个列表 然后赋值给key和value
key = hello, value = 1
4. 如果key存在result中了 那么他的值就加上变量value的值
如果key不存在result中 那么创建这个key 并将变量value赋值给它
{"hello": 1}
5. 继续从标准输入读取下一行 直到结束
6. 将结果格式化写入到标准输出
运行自己的MapReduce程序
需要将两个脚本拷贝到所有节点相同的目录哦 因为不知道哪个节点会被调度运算
1 | chmod +x mapper.py reducer.py |
使用 hadoop-streaming 跑起来吧!1
2
3
4cd /usr/local/hadoop/share/hadoop/tools/lib # 这个jar包的路径
# 注意:下面两行是一条命令
hadoop jar hadoop-streaming-2.7.5.jar -input /test.txt \
-output /pyout -mapper /tmp/mapper.py -reducer /tmp/reducer.py
命令参数什么的就不用说了吧 使用也是非常简单
PS: 前期想测试下自己写的程序 可以使用管道模拟 比如 cat test.txt | ./mapper.py | ./reducer.py
也可以试试Linux的命令作为 mapper 和 reducer 的处理程序哦 比如1
2hadoop jar hadoop-streaming-2.7.5.jar -input /test.txt \
-output /linuxout -mapper /usr/bin/sort -reducer /usr/bin/uniq
跑完了 有没有很开心呢
接下来该看看结果是否和自带的wordcount一样呢
root@slave1:~# hadoop fs -ls /pyout
Found 2 items
-rw-r--r-- 2 root supergroup 0 2018-02-08 15:44 /pyout/_SUCCESS
-rw-r--r-- 2 root supergroup 95 2018-02-08 15:44 /pyout/part-00000
root@slave1:~# hadoop fs -cat /pyout/part-00000
hi 1443776
c++ 360944
c 360944
world 360944
java 721888
lua 721888
python 721888
hello 1804720
wordcount果然是大数据的Hello World
学习到这里 也算是进入大数据的大门了 接下来就学习更高级的内容吧
附录
学习过的资料
遇到的问题
- 如果主节点重新格式化了 子节点也需要将数据目录中的文件都删除
- 遇到会持续更新。。。